
Where people look is critical to visual communication

Traditionally, techniques to influence where you look involve editing pixels by applying filters such as a blur or vignette to an image.

However, people are incredible fake discriminators and we can spot that those pixels have been manipulated in a way that doesn't reflect the real world.
In this project we explore creating generative models that influence where people look in an image to match the artist intent while keeping the final image inside the manifold of plausible realistic images.

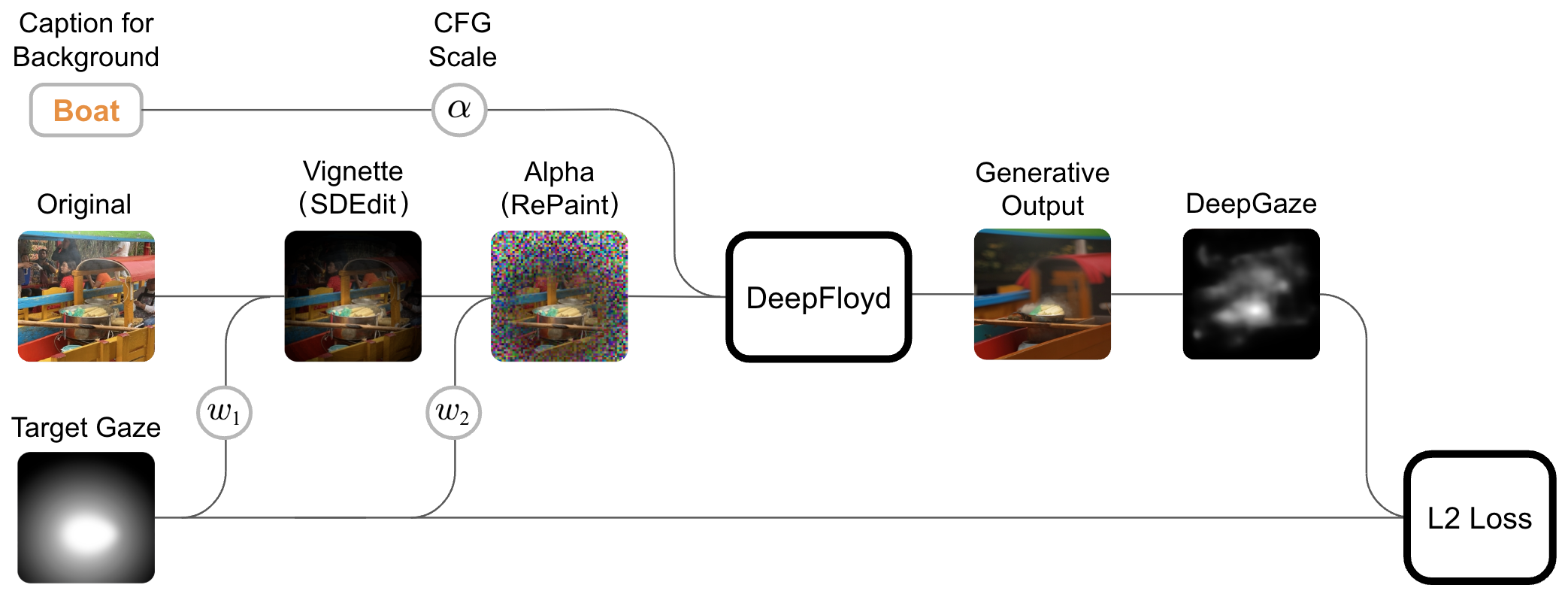
We leverage existing state of the art deep learning models for gaze estimation (DeepGaze) and generative techniques such as SDEdit and RePaint to create a Diffusion based architecture to induce the average viewer to look towards a mask painted by the user.
We apply the same vignette technique as mentioned before, but additionally we pass the image
through SDEdit to ask, "How could we achieve this look while keeping the image within the manifold of
realistic
images?"
In the result below you can see that it added more density to the foliage of the trees in order to
achieve a "Natural vignette" effect.
As a design choice, we utilized the architecture proposed by RePaint to give the artist the option to preserve
the pixels in the area they want to draw attention (as specified by the target gaze map). To maintain context
of the image, in the inverse of that mask, we use text prompt conditioning and CFG scale to allow for a
re-imagining of the scene that might reduce distraction from the target gaze map.
People are one of the
strongest gaze attractors in image. In the example below, you can see that the person in the yellow shirt is
still present in the generated image, but they are much smaller and facing away from the camera (looking towards
the temple).

Leveraging the state of the art model for gaze estimation DeepGaze, we can estimate where people will look in an image.

Utilizing this gaze estimation, we can compute an L2 loss between the target gaze map and the
target gaze map authored by the user. We experimented training a fine-tune layer on the diffusion model to
utilize the gradient of the L2 loss, however all of the images in this project were generated by random sampling
of the model and then using the L2 loss to sort the images that best match our goals.
Much like project 5, we utilize the pre-traiened diffusion model DeepFloyd as the
backbone of our generative model.
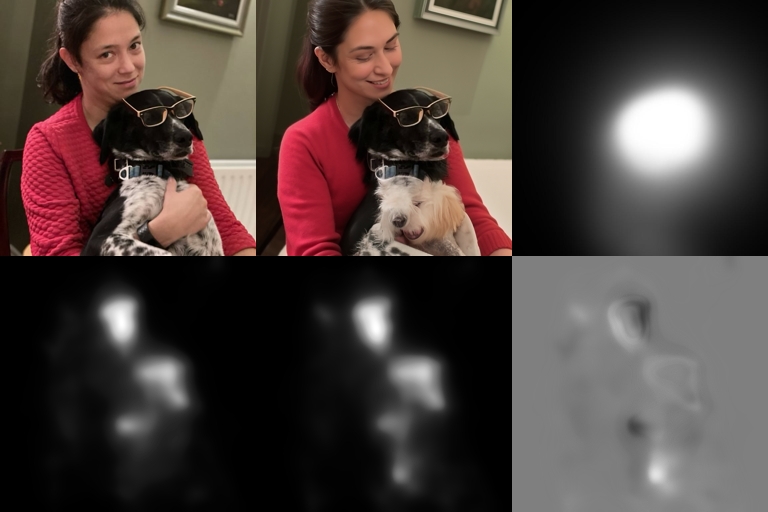
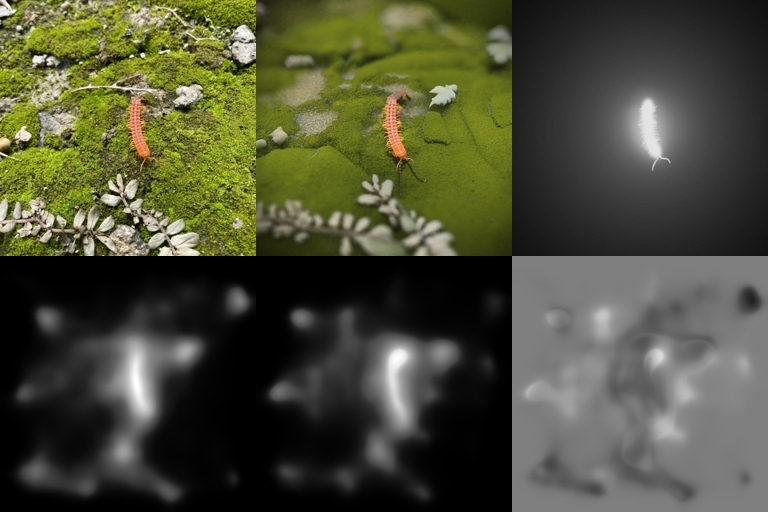
The figure below explains how to interpret the results. The "Orig-Gen gazemap delta" (bottom right) is the result of subtracting the gaze map from the original image, from the gaze map of the generated image. It allows you to see how the edits affected DeepGaze's predictions of where people would look.

An interesting interpretation of the vignette as of *steam* on the corn. This is very different than effects traditionally achieved in Photoshop (pre-generative AI techniques).

The target gaze for this image is particularly interesting as the area of interest is spatially not centered and off to the right. In the orig-gen gaze delta (bottom right) one can see how the removal of the other helmets removed visual distractions.

A bokeh effect that is hallucinated which is cool given there is no equivalent filter in Photoshop that can achieve this.

The following three examples seem to change the person's gaze towards the object of interest (represented by the target gaze map).


We see an artifact of the hand becoming another dog.
The birds are removed from the image, the canoe color is simplified, a "natural vignette" is achieved with the clouds.

The area below the centipede is simplified and a blur and vignette effect is applied.
This one shows a dramatic interpretation of the pixels outside of the target gaze map. It makes the person in the yellow shirt smaller and facing away. Darkening the sky.

Another example of the same original image.

A simplification of the rocks below her.

While the main effect is that of blur, notice the background's color and shape complexity is simplified.

As mentioned before, we intend to fine tune the model to follow the gradient of the L2 Loss to allow for more efficient sampling (for this project we did random sampling).
We have access to AR glasses (Meta Aria), which have eye-tracking capabilities. With this hardware we could validate the gaze map predictions of our generations.
We started to explore automating the target gaze map with simple mouse clicks on an image by leveraging state of the art monocular depth estimating models such as Marigold. Below we show how based on a mouse click we could manipulate the depth information to be object centric rather than camera centric:



We wanted to try to apply the vignette to the lower frequencies of the image and preserve the high frequencies. This would allow for a more natural looking vignette effect.
If you subtract the target gaze map from the original image's gaze map prediction you essentially get a mask of the distracting areas. We want to explore using this as a mask for RePaint.
For storytelling purposes, the ability to induce gaze order sequence would be a powerful tool!
In art, it's often useful to thumbnail a composition of an image before creating the full image. Intuitively you can imagine how computing gaze manipulation from our model at multiple resolutions might improve our results.
As you can tell by the long list of items in our future work section, this class has filled us with passion for exploring the possibilities of computer vision, generative models, and creating beautiful art. Thank you so much for everything!!!